
Neural networks are the reason your phone recognizes your face, a car can detect pedestrians, and a search engine completes your sentence before you finish typing. At their core, they’re not magical they’re function approximators that learn patterns from examples. But when you stack simple functions into many layers and let them learn together, you get systems that can spot edges in photos, detect sentiment in a paragraph, and even write working code. This post demystifies that stack, from the shape of a network to how it trains and why it generalizes, with visuals you can keep in your head.
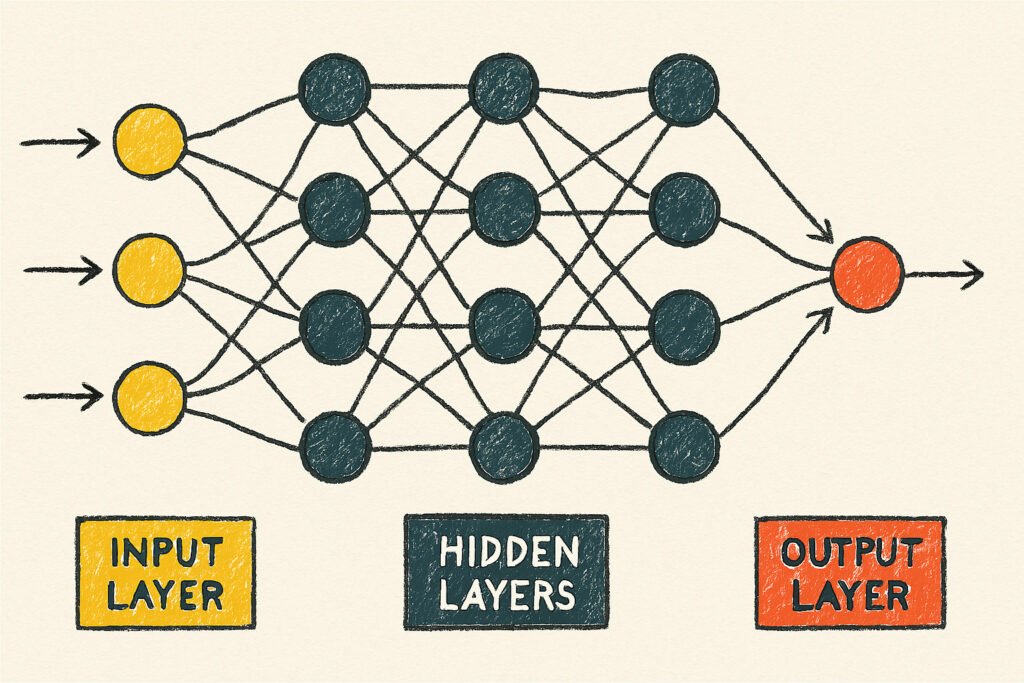
A network is a sequence of transformations
A neural network is a sequence of linear transforms (matrix multiplies) with non-linear activations in between. Each layer turns raw input into a slightly more useful representation; stack enough layers and raw pixels can become “cat.”
In practice, two ideas matter most:
- Depth vs. width: Depth (more layers) builds abstraction; width (more neurons) adds capacity. Balance both to learn the signal without memorizing noise.
- Representations: Early layers learn generic features (edges, frequencies); later layers compose them into concepts (wheels, faces, sentiment).
Why linear rules aren’t enough and where nonlinearity wins
A single linear layer is a straight line in disguise. Real-world problems voices in a crowded room, objects at odd angles, fraudsters hiding in data aren’t separated by straight lines. The trick is to interleave linear layers with nonlinear functions (ReLU, GELU, sigmoid). Those kinks let networks carve complex, curvy decision boundaries that fit the messy contours of reality.
The image above shows a tiny network learning to split two crescent-shaped clusters. A linear model can’t separate these; a network with nonlinear activations can.

How the learning actually happens
Training is an experiment run thousands of times per minute. We start with random weights, make a prediction, measure the error (the loss), and adjust the weights via backpropagation so the next prediction is a little less wrong. Repeat over batches until improvement stalls.
A few high-leverage practices:
- Hold-out validation: Keep data aside you never train on; it’s your reality check.
- Regularization: Dropout, weight decay, and data augmentation reduce overfitting.
- Monitoring after launch: Track accuracy/latency/drift and bias metrics continuously
Convolutions: the eyes of modern vision systems
For images, fully connected layers waste parameters. Convolutional layers reuse small filters across the image, learning edge and texture detectors that tile the field of view. This weight sharing is efficient and translation-friendly, which is why convolutional networks powered the leap in computer vision.
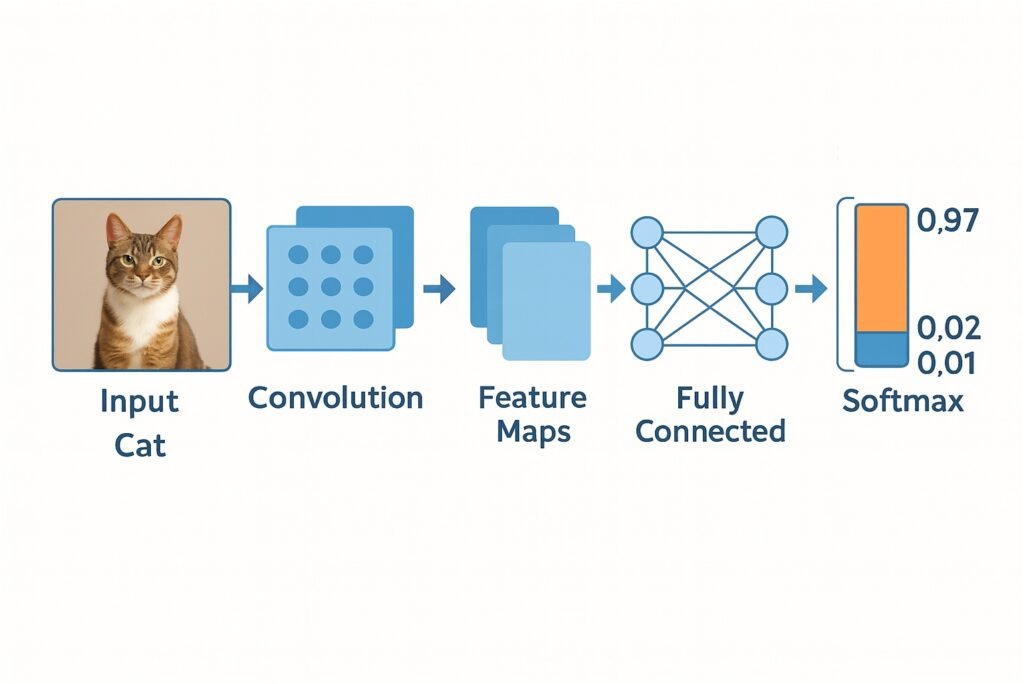
Each filter is a pattern detector; deeper layers combine detectors into motifs and objects. The same idea extends to audio (time-frequency maps) and even tabular data when local patterns matter.
Picking the Right Architecture
Convolutional networks are still workhorses for images, but transformers now dominate language and, increasingly, vision and speech. Recurrent networks remain useful for streaming signals and low-latency on-device tasks. In practice, start with the simplest architecture that fits your constraints (data size, latency, memory), then scale up with better regularization and pretraining before you throw more layers at the problem.
- Images/video: Start with conv nets or vision transformers; use pretrained weights.
- Language & multimodal: Transformers dominate; leverage foundation models, fine-tune lightly.
- Time-series/streaming: Small convs, gated RNNs, or compact transformers for low latency.
From Prototype to Production
Great models are maintained, not just trained. The playbook that scales:
- Clear objective & constraints: Target metric, latency budget, memory limits.
- Baselines first: A strong logistic/gradient-boosted baseline keeps you honest.
- Data contracts: Versioned datasets and schemas prevent silent breakage.
- Observability: Input drift, output quality, fairness dashboards, and rollback.
The ethics and engineering that make it real
Neural networks mirror the data we feed them. If past decisions were biased, a model can learn those patterns perfectly. Responsible systems pair model quality with governance: dataset documentation, bias audits, human oversight, rollback plans. Equally important is observability watching inputs, outputs, and performance drift over time so the model stays aligned with reality and your values.
Neural networks learn patterns ncluding undesirable ones. Responsible teams:
- Audit for disparate performance across groups.
- Document datasets (provenance, limitations).
- Keep a human-in-the-loop for high-stakes calls.
- Plan rollbacks and incident response before shipping.
A neural network is a stack of simple functions whose parameters are tuned by gradient descent to approximate a complex mapping. Every architectural trick attention, normalization, residuals exists to make that approximation more expressive, stable, and efficient.
Leave a Reply