
We don’t program computers with rules anymore, we teach them with examples
Your phone guesses your route before you decide. A camera brightens a face without asking. A bank blocks a thief mid-purchase. None of this came from a giant rulebook. It came from machine learning (ML) software that learns patterns from data and keeps improving with feedback.
The loop behind modern AI: collect data → turn it into useful signals → train a model → test on new data → deploy and monitor as the world shifts.
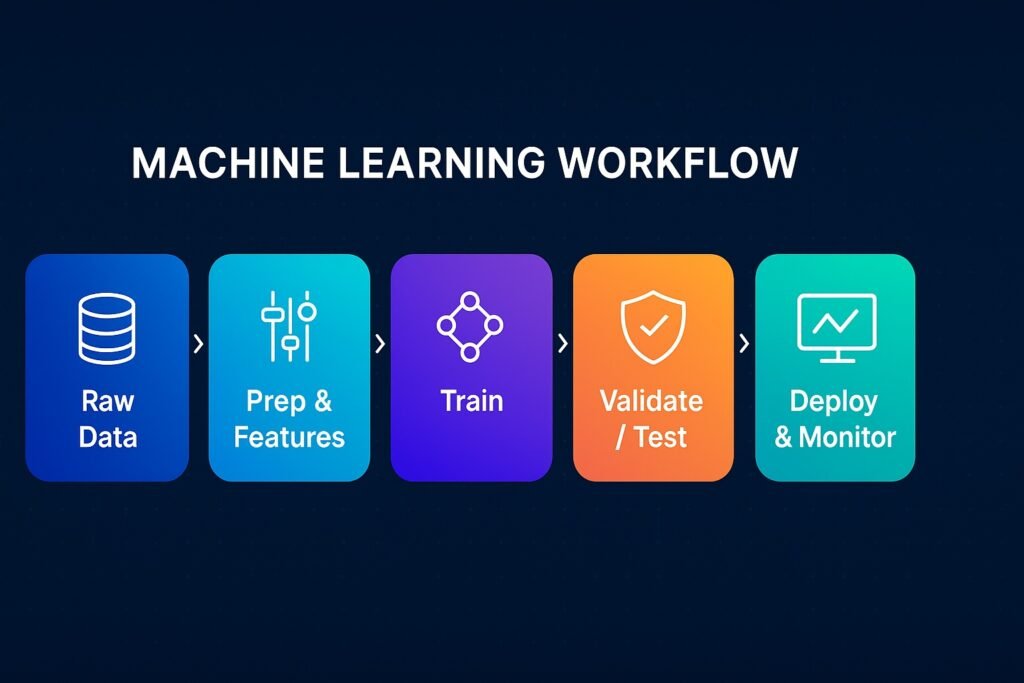
What ML Really Is
Traditional code: “IF this happens, THEN do that.”
ML: “Here are 100,000 examples figure out what usually works, then adjust when you’re wrong.”
Under the hood, it’s just organized trial-and-error:
- Show examples (emails tagged spam/ham).
- Measure error (how wrong the model is).
- Nudge the knobs (its “weights”) to be less wrong next time.
- Repeat forever, because people and patterns change.
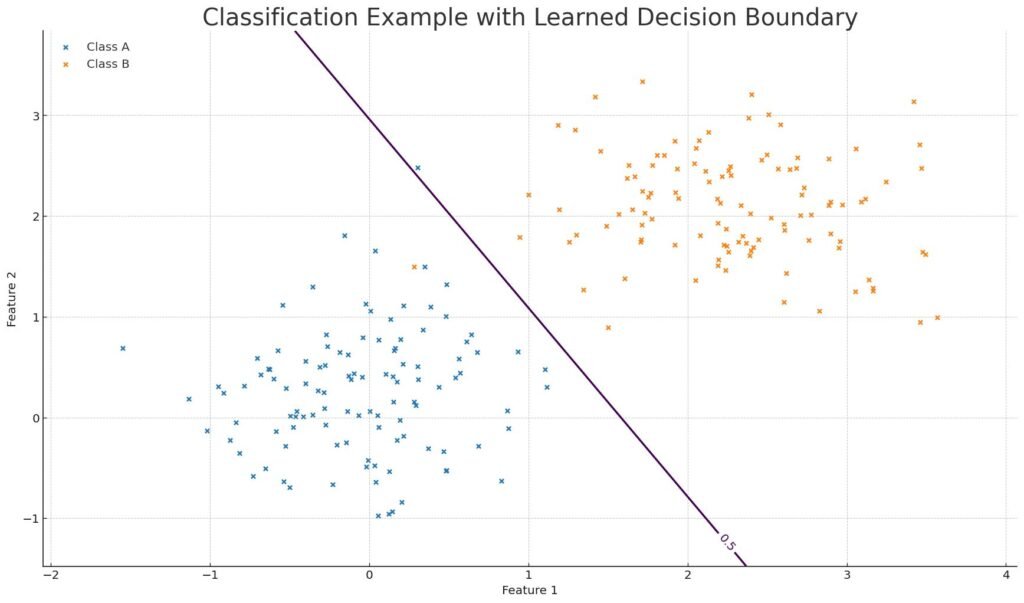
A Visual Intuition
Each dot is an example. The model learns a boundary that splits classes. Training just moves this boundary to reduce future mistakes. That’s the whole game, from spam filters to face unlock at planet-scale.
Where You Already Meet ML
- What to hide: spam filters
- What to show: recommendations & feeds
- What will happen: delivery ETAs, fraud alerts
- What’s in the picture: cameras, vision, OCR
- What to say next: autocomplete, translation
No hard-coded rules just patterns distilled from oceans of examples.
The Five Flavors in Machine Learning
- Supervised: labeled outcomes (“cat / not cat”, “churn / stay”).
- Unsupervised: no labels find structure (customer segments).
- Self-supervised: labels from the data itself (predict the next word).
- Reinforcement: learn by reward (robots, game-playing).
- Generative: create text, images, code (your copilot).
Quick chooser:
- Need a yes/no, number, or category? → Supervised
- Want natural groupings? → Unsupervised
- Creating content or summaries? → Generative
- Learning by doing with goals? → Reinforcement
Myths vs Reality
- Myth: “ML needs infinite data.”
- Reality: Good data > more data. Quality and diversity win.
- Myth: “Deep learning is always best.”
- Reality: Start simple. Baselines beat buzzwords surprisingly often.
- Myth: “Once trained, you’re done.”
- Reality: Data drifts. Monitoring is half the work.
- Myth: “Models are neutral.”
- Reality: Bias in → bias out. Measure, mitigate, review
The Field-Tested Playbook
- Define success. “Improve approval accuracy by 4% without raising false declines.”
- Start with a baseline. A simple model creates a trustworthy yardstick.
- Protect your test set. No peeking; avoid data leakage.
- Ship small, monitor hard. Track accuracy, latency, bias, and drift.
- Close the loop. Use real-world feedback to retrain (and roll back fast).
Minimal Jargon
- Model: the thing making predictions.
- Weights/parameters: the dials it tunes while learning.
- Loss: how wrong it is (lower is better).
- Inference: using the trained model to predict.
- Features: input signals the model can use.
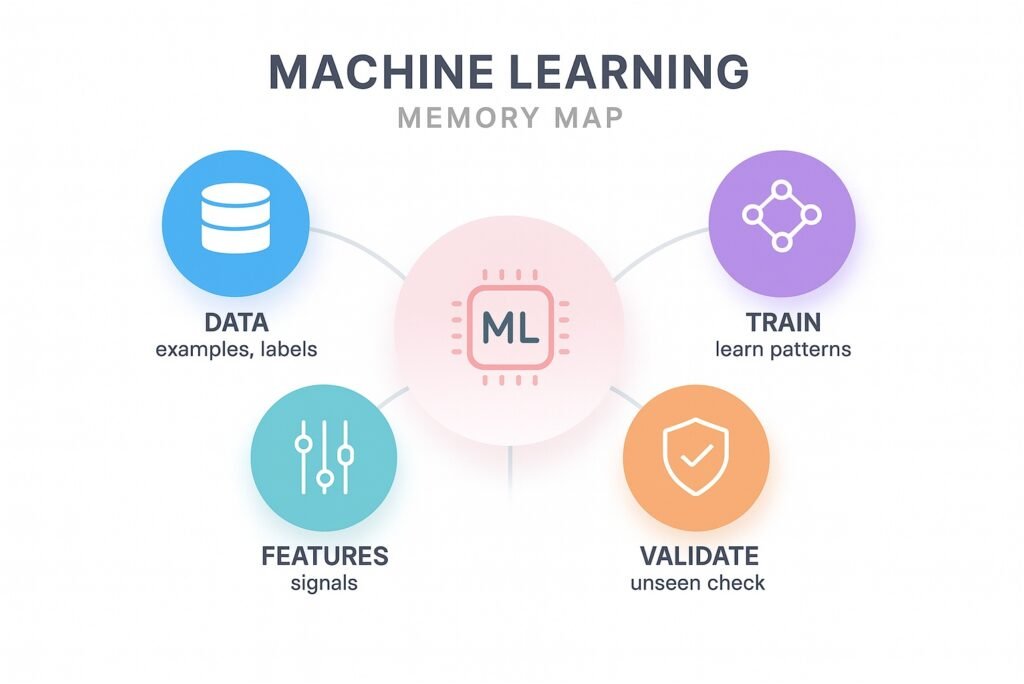
Machine learning is how software learns from examples and keeps learning as reality shifts. The secret isn’t a fancier model; it’s tight feedback loops, honest evaluation, and relentless monitoring.
Leave a Reply